完整代码实现及训练与测试数据:
一、任务描述
自然语言通顺与否的判定,即给定一个句子,要求判定所给的句子是否通顺。
二、问题探索与分析
拿到这个问题便开始思索用什么方法来解决比较合适。在看了一些错误的句子之后,给我的第一直觉就是某些类型的词不应该拼接在一起,比如动词接动词(e.g.我打开听见)这种情况基本不会出现在我们的用语中。于是就有了第一个idea基于规则来解决这个问题。但是发现很难建立完善的语言规则也缺乏相关的语言学知识,实现这么完整的一套规则也不简单,因此就放弃了基于规则来实现,但还是想抓住某些类型的词互斥的特性,就想到了N-Gram,但是这里的N-Gram不是基于词来做,而是基于词的词性来做。基于词来做参数量巨大,需要非常完善且高质量的语料库,而词的词性种类数目很小,基于词性来做就不会有基于词的困扰,而且基于词性来做直觉上更能贴合想到的这个idea。除了这个naive的idea之外,后面还有尝试用深度学习来学习句子通顺与否的特征,但是难点在于特征工程怎么做才能学习到句子不通顺的特征。下面我会详细说明我的具体实现。
三、代码设计与实现
3.1 基于词性的N-Gram
环境:
python 3.6.7
- pyltp 0.2.1(匹配的ltp mode 3.4.0)
numpy 1.15.4
pyltp用于分词和词性标注,首先加载分词和词性标注模型
from pyltp import Segmentorfrom pyltp import Postaggerseg = Segmentor()seg.load(os.path.join('../input/ltp_data_v3.4.0', 'cws.model'))pos = Postagger()pos.load(os.path.join('../input/ltp_data_v3.4.0', 'pos.model'))加载训练数据,并对数据进行分词和词性标注,在句首句尾分别加上<s>和</s>作为句子开始和结束的标记
train_sent = []trainid = []train_sent_map = {} #[id:[ngram value, label]]with open('../input/train.txt', 'r') as trainf: for line in trainf: if len(line.strip()) != 0: items = line.strip().split('\t') tags = [''] for tag in pos.postag(seg.segment(items[1])): tags.append(tag) tags.append('') train_sent.append(tags) trainid.append(int(items[0])) train_sent_map[trainid[-1]] = [0.0, int(items[2])]测试数据的加载方式与训练数据一致不再赘述,接下来就是对训练数据中标签为0的数据进行1gram和2grams的词性频率计数
train_1gram_freq = {}train_2grams_freq = {}for sent in test_sent: train_1gram_freq[sent[0]] = 1 for j in range(1, len(sent)): train_1gram_freq[sent[j]] = 1 train_2grams_freq[' '.join(sent[j-1:j+1])] = 1e-100for i in range(len(trainid)): if train_sent_map[trainid[i]][1] == 0: sent = train_sent[i] train_1gram_freq[sent[0]] = 0 for j in range(1, len(sent)): train_1gram_freq[sent[j]] = 0 train_2grams_freq[' '.join(sent[j-1:j+1])] = 0# 预处理训练集0标记的正确句子for i in range(len(trainid)): if train_sent_map[trainid[i]][1] == 0: sent = train_sent[i] train_1gram_freq[sent[0]] += 1 for j in range(1, len(sent)): train_1gram_freq[sent[j]] += 1 train_2grams_freq[' '.join(sent[j-1:j+1])] += 1由于测试数据中可能包含训练数据中未包含的词性组合,用python的dict存储词性到频度的映射,在对测试集中句子的N-Gram概率进行计算时会报KeyError的错误。为了解决这个问题,就有了上面看起来似乎有点冗余的代码。先将测试集中1gram和2grams的词性写到dict中,这样就至少保证了不会出现KeyError的错误。然后将训练集中1gram和2grams的词性写到dict中,覆盖了测试集写入的相同的key,再进行频度计数。对于只在测试集中出现的key还保留着原来的值,这里对测试集中的2grams组合赋值为1e-100是为了在计算2-Grams模型概率值时突显出未在训练集中出现的特征,从而能够从测试集中辨识出这些异常的句子。
由于句子长短不一,计算出来的句子的概率差距甚远,所以需要对相同长度的句子进行一个聚类,然后用计算出来的概率值除以句子字长,这样才能保证句子的概率基本保持在一个较小的范围内,设置的阈值才能较好地将不同类型句子区分开来。
# 计算句子基于2-grams的概率值def compute_2grams_prob(sent, train_1gram_freq, train_2grams_freq): p = 0.0 for j in range(1, len(sent)): p += math.log(train_2grams_freq[' '.join(sent[j-1:j+1])] * 1.0 \ / train_1gram_freq[sent[j-1]]) return p / len(sent)# 计算训练集中句子的概率值for i, sent in enumerate(train_sent): if train_sent_map[trainid[i]][1] == 0: train_sent_map[trainid[i]][0] = compute_2grams_prob(sent, train_1gram_freq, train_2grams_freq)# 对不同长度的句子进行聚类,然后计算等长句子类的平均概率值train_samesize_avgprob = {}for i, sent in enumerate(train_sent): train_samesize_avgprob[len(sent)] = [0.0, 0]for i, sent in enumerate(train_sent): train_samesize_avgprob[len(sent)][0] += train_sent_map[trainid[i]][0] train_samesize_avgprob[len(sent)][1] += 1for key in train_samesize_avgprob.keys(): train_samesize_avgprob[key][0] = train_samesize_avgprob[key][0] / train_samesize_avgprob[key][1]统计训练集中2-Grams概率的最小值,最大值,以及平均值,其中平均值将被用作判断句子好坏的阈值
thresh = {'min0':0.0, 'max0':-np.inf, 'avg0':0.0}c0 = 0for id in trainid: if train_sent_map[id][1] == 0: if train_sent_map[id][0] < thresh['min0']: thresh['min0'] = train_sent_map[id][0] if train_sent_map[id][0] > thresh['max0']: thresh['max0'] = train_sent_map[id][0] thresh['avg0'] += train_sent_map[id][0] c0 += 1thresh['avg0'] /= c0接着计算测试集中每个句子基于2-Grams的除以字长的概率值,然后与由训练集计算得到的与其等字长类的平均概率值进行对比。如果训练集中没有找到与测试集中某个句子的等长的句子,则测试集中该句子概率值直接去总体训练样本计算得到的概率值进行对比。
thresh_tx = {'min':0.0, 'max':-np.inf, 'avg':0.0}TX = []with open('../output/ngramfluent_postag_pyltp.txt', 'w') as resf: for sent in test_sent: TX.append([compute_2grams_prob(sent, train_1gram_freq, train_2grams_freq)]) for i in range(len(TX)): if thresh_tx['min'] > TX[i][0]: thresh_tx['min'] = TX[i][0] if thresh_tx['max'] < TX[i][0]: thresh_tx['max'] = TX[i][0] thresh_tx['avg'] += TX[i][0] thresh_tx['avg'] /= len(TX) print('测试集:', thresh_tx) for i in range(len(testid)): if len(test_sent[i]) in train_samesize_avgprob.keys(): if TX[i][0] >= train_samesize_avgprob[len(test_sent[i])][0]: resf.write(testid[i] + '\t0\n') else: resf.write(testid[i] + '\t1\n') else: if TX[i][0] >= thresh['avg'] - 0.1: resf.write(testid[i] + '\t0\n') else: resf.write(testid[i] + '\t1\n')thresh['avg']-0.1之后再比较是因为训练集基于2-Grams计算的概率平均值与测试集基于2-Grams计算的概率平均值相比有一点小小上下波动,减0.1相当于一个微调的优化操作。
以上便是基于词性的2-Grams方法的具体实现,最后提交的结果65%的样子,同时我也使用了直接基于词的2-Grams方法,但是提交的结果没有基于词性的方法好,应该是语料库内容不足以支撑,然后我又尝试将wiki中文数据集内容提取出来并划分成句子作为正类输入,但是结果还是没有基于词性的好,可能是wiki数据集太大,而我处理得很粗糙,数据清洗工作不到位导致的。
3.2 深度学习学习句法特征
环境:
python 3.6.7
bert-serving-server
bert-serving-client
sklearn
numpy
深度学习我没有系统地学过,Google最近提出的bert很火,于是就想尝试使用bert来基于句子做特征工程,学习病句特征,然后再用SVM做一个分类。都是调用的接口,代码很少,但是最后效果却很差。可能是bert参数没调好,但是目前对bert了解甚少不知该怎么调,而时间有限所以也就没进一步深入了。后续有时间学习一下bert再回过头来优化模型。
四、性能分析
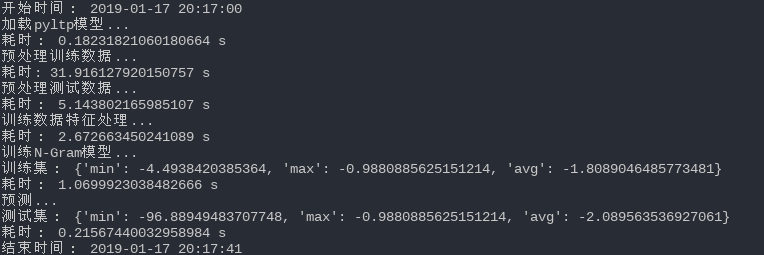
使用基于统计的方法做计算复杂度很低,除去分词模块,2-Grams模型的计算复杂度为O(样本数*句子平均字长),所以代码运行起来很快,下面是代码运行截图:
五、遇到的问题及解决方案
对于未包含在训练集中的测试集2-Grams,在计算概率值时怎么做平滑处理?
具体解决方案在第三节中有详细描述。
不同句长的句子基于2-Grams计算出来的log概率值相差甚远,这给设置分类阈值带来了麻烦,该如何解决?
计算得到的概率值除以句子字长,具体实现时还加入了等句长的聚类,详细解决方案在第三节中有描述。
概率比对阈值设置多大才能最准确地进行分类?
这个问题我目前也没有很好的解决方法,只能多试几个看看实际的结果。
六、未来改进
估计使用2-Grams方法的瓶颈不到70%,当下深度学习在NLP中应用很火热,未来可以深入学习以下深度学习在NLP中的应用然后再回过头来用深度学习的视角来重新看待这个问题。